그동안 주로 프론트엔드에 집중해 왔지만, 운 좋게? AI 관련 회사들에서 경험을 쌓을 수 있었다. 첫 회사에서는 음성 인식(STT) 을 다루는 곳이었고, 현재 다니고 있는 회사 역시 스캔 데이터을 활용한 AI 서비스를 만들고 있다.
겉으로 보기에는 사용자에게 보이는 화면을 만드는 프론트엔드 개발자였지만, AI가 포함된 서비스를 접할 기회가 많았다.
변화하는 시장과 새로운 고민
최근 원티드나 잡코리아 같은 채용 사이트를 보면, 많은 회사들이 LLM(Large Language Model) 기반 사업을 활발히 진행하고 있다. 단순한 검색이나 추천 시스템을 넘어, 대화형 서비스, 데이터 요약, 지능형 상담 등 다양한 분야에서 LLM이 접목되고 있는 것 같다.
실제로 이런 프로젝트들을 경험해보니, 단순히 프론트엔드 영역만으로는 완결되지 않는다는 점을 몸으로 느낄 수 있었다. LLM 기반 서비스의 로직은 대부분 백엔드에서 처리되고, 프론트엔드는 그 결과를 사용자에게 보여주는 역할을 맡는다. 따라서 프론트엔드만 이해하고 있으면 전체 서비스가 어떻게 동작하는지 파악하기 어렵고, 사용자 경험을 최적화하기도 쉽지 않았다…
현재 회사에서도 진단 기록 관련 LLM 사업을 진행 중인데, 나는 백엔드에서 처리된 AI 결과를 받아서 사용자에게 잘 보여주는 역할을 담당하고 있다. 하지만 그 ‘처리 과정’에 대해서는 궁금증이 생겼고, 백엔드에서 AI를 어떻게 효율적이고 구조적으로 활용하고 있는지 알고 싶어졌다.
프론트엔드와 AI의 접점
프롬프트를 잘 작성하면 LLM의 응답을 어느 정도 제어할 수 있다. “3줄로 요약해줘"보다는
| “다음 형식으로 정확히 3줄로 요약해줘: 1. … 2. … 3. …”
처럼 구체적으로 작성하면 더 일관된 결과를 얻을 수 있다.
하지만 프롬프트만으로 모든 문제를 해결할 수는 없다. LLM 기반 서비스에서 프론트엔드 개발자가 고려해야 할 것들이 더 많다. 단순히 화면에 답변을 보여주는 것만으로는 충분하지 않다. 프론트엔드는 사용자가 이해하고 신뢰할 수 있는 방식으로 결과를 전달해야 하고, 그러려면 LLM이 어떤 구조로 동작하는지, 백엔드에서 어떻게 처리되는지 이해할 필요가 있다.
예를 들어:
- 사용자 입력이 백엔드로 전달되어 모델이 응답을 생성하고, 다시 프론트엔드로 결과가 전달되는 전체 흐름
- 프롬프트 템플릿, 체인, 메모리 같은 구조를 이해하면 프론트엔드에서 더 나은 UX를 제공할 수 있음
- 스트리밍 응답 처리, 로딩 상태 관리, 에러 핸들링, 응답 포맷팅 등 프론트엔드에서 처리해야 할 부분들
이처럼, 프론트엔드는 사용자 경험을 책임지고, 백엔드는 LLM과 데이터를 다루는 엔진 역할을 한다. 프론트엔드 개발자가 백엔드의 AI 처리 구조를 이해할수록, 더 나은 사용자 경험을 만들 수 있다.
LangChain과 LangGraph: LLM 다루기
LLM을 서비스에 연결하려면 모델 호출만으로는 충분하지 않다. 데이터 흐름, 로직 구성, 예외 처리 등을 체계적으로 관리해야 한다. 이를 도와주는 것이 LangChain이다.
LangChain이란?
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발에 특화된 오픈소스 프레임워크다. Python과 JavaScript 기반 라이브러리 모두에서 사용 가능하며, 챗봇과 가상 에이전트와 같은 LLM 기반 애플리케이션을 구축하는 과정을 간소화한다.
처음 LangChain을 접했을 때는 “이게 뭐가 다른 거지?“라고 생각했는데, 실제 코드를 보니 차이가 컸다. 그냥 OpenAI API를 직접 호출하는 것보다 훨씬 구조적으로 관리할 수 있었다.
React에서 컴포넌트를 조합하는 것과 비슷한 느낌이랄까? 각각의 기능들을 모듈화해서 조합하는 방식이 꽤 직관적이었다.
핵심 구성 요소들
- 1. Chains (체인) - 여러 단계를 연결해서 작업을 수행한다
- 2. Memory (메모리) - 대화 맥락을 유지하고 기억한다
- 3. Prompts (프롬프트 템플릿) - 재사용 가능한 프롬프트를 관리한다
- 4. Tools (도구) - 외부 API나 데이터베이스를 연결한다
간단한 활용 예시
사용자의 텍스트 입력을 받아 요약 결과를 만드는 과정을 비교해보자.
LangChain 없이 직접 구현할 때
import openai
import json
# 대화 기록을 저장할 변수 (메모리 역할)
conversation_history = []
def summarize_text(text):
# 프롬프트 구성
prompt = f"이 텍스트를 요약해줘:\n{text}"
# 이전 대화 기록을 프롬프트에 추가
if conversation_history:
history_context = "\n".join(conversation_history)
prompt = f"이전 대화:\n{history_context}\n\n{prompt}"
# OpenAI API 직접 호출
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
result = response.choices[0].message.content
# 대화 기록에 추가
conversation_history.append(f"사용자: {text}")
conversation_history.append(f"AI: {result}")
return result
# 실행
result = summarize_text("오늘 회의에서는 ...")
LangChain을 사용할 때
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
# 모델과 메모리 준비
llm = OpenAI(temperature=0)
memory = ConversationBufferMemory()
# 프롬프트 정의
prompt = PromptTemplate(
input_variables=["text"],
template="이 텍스트를 요약해줘:\n{text}"
)
# 체인 구성
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
# 실행
result = chain.run("오늘 회의에서는 ...")
LangChain 없이 직접 구현하면:
- 메모리 관리: 대화 기록을 수동으로 저장하고 관리해야 함
- 프롬프트 구성: 매번 프롬프트를 직접 조합해야 함
- 에러 처리: API 호출 실패, 토큰 제한 등을 직접 처리해야 함
- 확장성: 새로운 기능 추가 시 코드가 복잡해짐
LangChain을 사용하면:
- 자동 메모리 관리: 대화 맥락을 자동으로 유지
- 재사용 가능한 프롬프트: 템플릿으로 관리하여 일관성 확보
- 체인 구조: 각 단계를 모듈화하여 관리
- 확장성: 새로운 도구나 메모리 타입을 쉽게 추가 가능
이 예제에서 LangChain은 사용자 입력 → 프롬프트 → 모델 호출 → 메모리 반영의 흐름을 하나의 체인 안에서 관리해준다. 이전 대화나 문서 컨텍스트를 기억하기 때문에 연속적인 요약이나 대화에서도 자연스럽게 활용할 수 있게된다.
LangGraph
LangGraph는 LangChain으로 구성한 체인과 도구들을 시각적으로 구성하고 관리할 수 있는 도구다. 체인 단계별로 데이터를 확인하고, 후속 단계에서 추가 로직이나 외부 API 호출도 쉽게 연결할 수 있다.
from langgraph import Graph, Node
graph = Graph()
# 노드 정의
input_node = Node("사용자 입력")
preprocess_node = Node("텍스트 전처리")
llm_node = Node("LLM 호출")
memory_node = Node("메모리 반영") # DB 연경
postprocess_node = Node("후처리")
# 노드 연결
graph.add_edges([
(input_node, preprocess_node),
(preprocess_node, llm_node),
(llm_node, memory_node),
(memory_node, postprocess_node)
])
# 그래프 실행
graph.run("오늘 회의에서는 ...")
이렇게 구성하면 각 단계가 어떻게 연결되어 있는지, 어떤 데이터가 다음 단계로 전달되는지 한눈에 확인할 수 있다.
실제 예시: STT → LLM → 요약 서비스
AI 요약 서비스의 일반적인 구성은 대략 다음과 같다.
음성 데이터 수집 & 텍스트 변환
Whisper(STT 모델)로 사용자의 음성을 텍스트로 변환한다.텍스트 전처리
불필요한 공백이나 특수문자 제거, 문장 단위 분리LLM 호출
전처리된 텍스트를 ChatGPT 모델에 프롬프트와 함께 전달
예: “이 텍스트를 회의 요약 형태로 정리해줘”후처리 & 프론트 전달
모델 반환 결과를 문단 나누기, 중요 키워드 강조 등으로 가공하여 프론트엔드로 전달
실제 워크플로우를 LangGraph로 표현하면 다음과 같다:
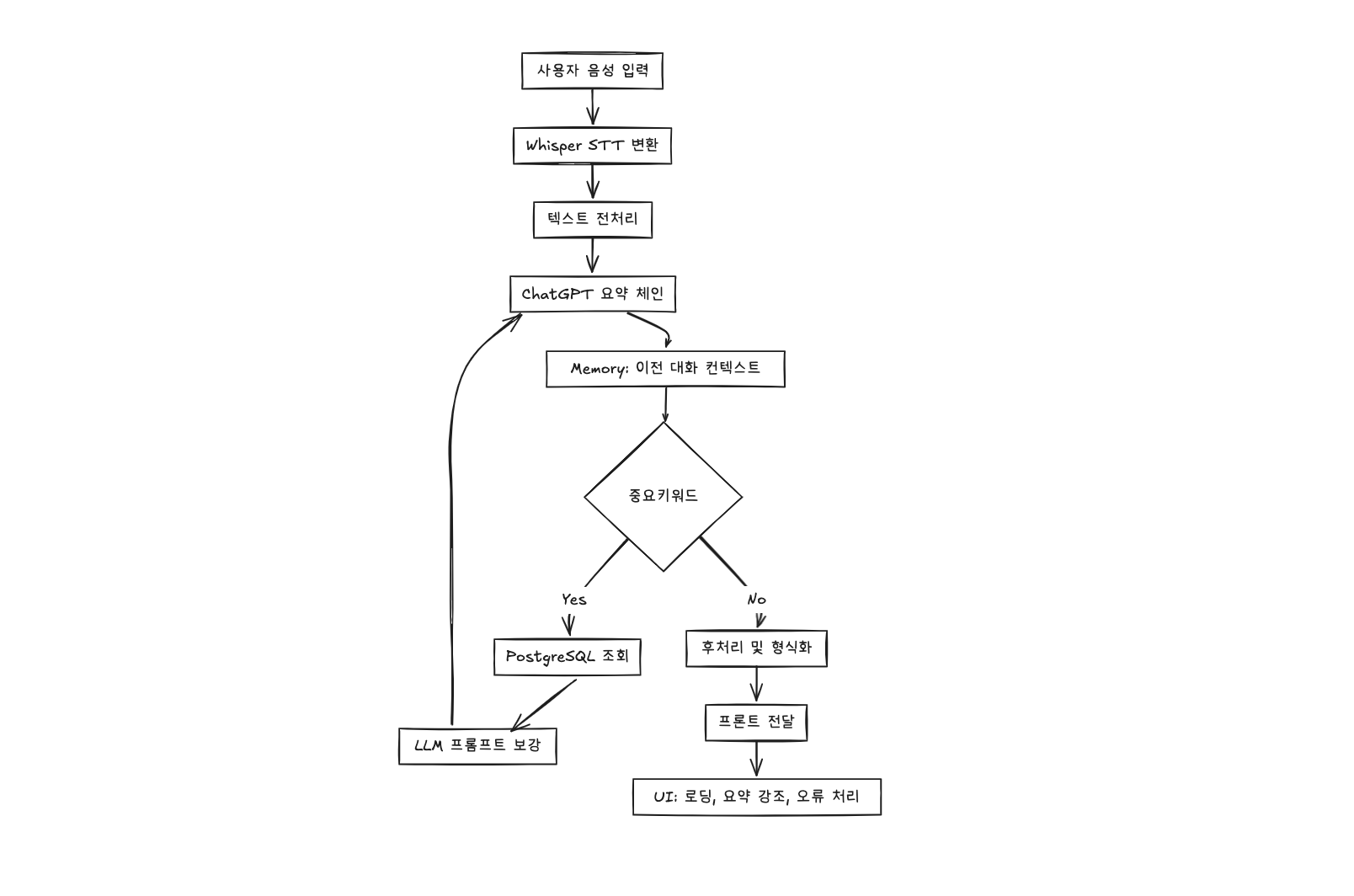
구조 이해의 중요성
LangChain을 사용하면 이러한 단계들을 체인, 메모리, 도구 단위로 관리할 수 있고, LangGraph를 통해 시각적으로 확인하며 필요한 단계에 외부 API나 DB 조회도 연결할 수 있다.
이렇게 구조를 이해하면, 단순히 모델을 호출하는 것을 넘어서 백엔드에서 LLM이 어떻게 동작하는지, 데이터가 어떻게 흐르는지를 체계적으로 파악할 수 있다.
마무리 하며
이번 글에서는 프론트엔드 관점에서 AI 서비스와 LLM 구조를 살펴보았지만, 실제로는 LangChain과 LangGraph를 직접 구성해보고, 각 단계에서 어떤 함수들이 사용되는지, 메모리나 외부 API는 어떻게 연결되는지를 탐구해보는 것이 다음 단계가 될 것 같다.
앞으로 사이드 프로젝트로 직접 구현하면서, 체인과 메모리, 도구를 다루는 함수를 하나씩 살펴보고, 이를 기반으로 자신만의 AI 기반 서비스 구조를 실험해보는 것이 좋은 학습이 될 것 같다…